COLUMN
コラム
2026年04月01日
700実験、680失敗でも人間より速い理由。自己改善AIエージェントの設計パターン完全ガイド
2026年3月7日、Andrej Karpathyが公開した「AutoResearch」は、わずか数日で21,000以上のGitHub starsを獲得し、AI開発コミュニティに衝撃を与えました。Shopify CEOのTobias Lütkeは、このシステムを一晩動かしただけで37回の実験を実行し、19%の性能向上を達成したと報告しています。
しかし、さらに驚くべきは、Karpathy自身が2日間で700回の実験を実行し、そのうち680回が失敗に終わったという事実です。成功率わずか2.9%。それでも、このシステムは人間よりも圧倒的に速く学習します。
本記事では、2026年3月に立て続けに発表されたAutoResearchとMeta Hyperagentsの2大事例をもとに、自己改善AIエージェントの設計原則を完全解説します。
なぜ今「自己改善AIエージェント」なのか?
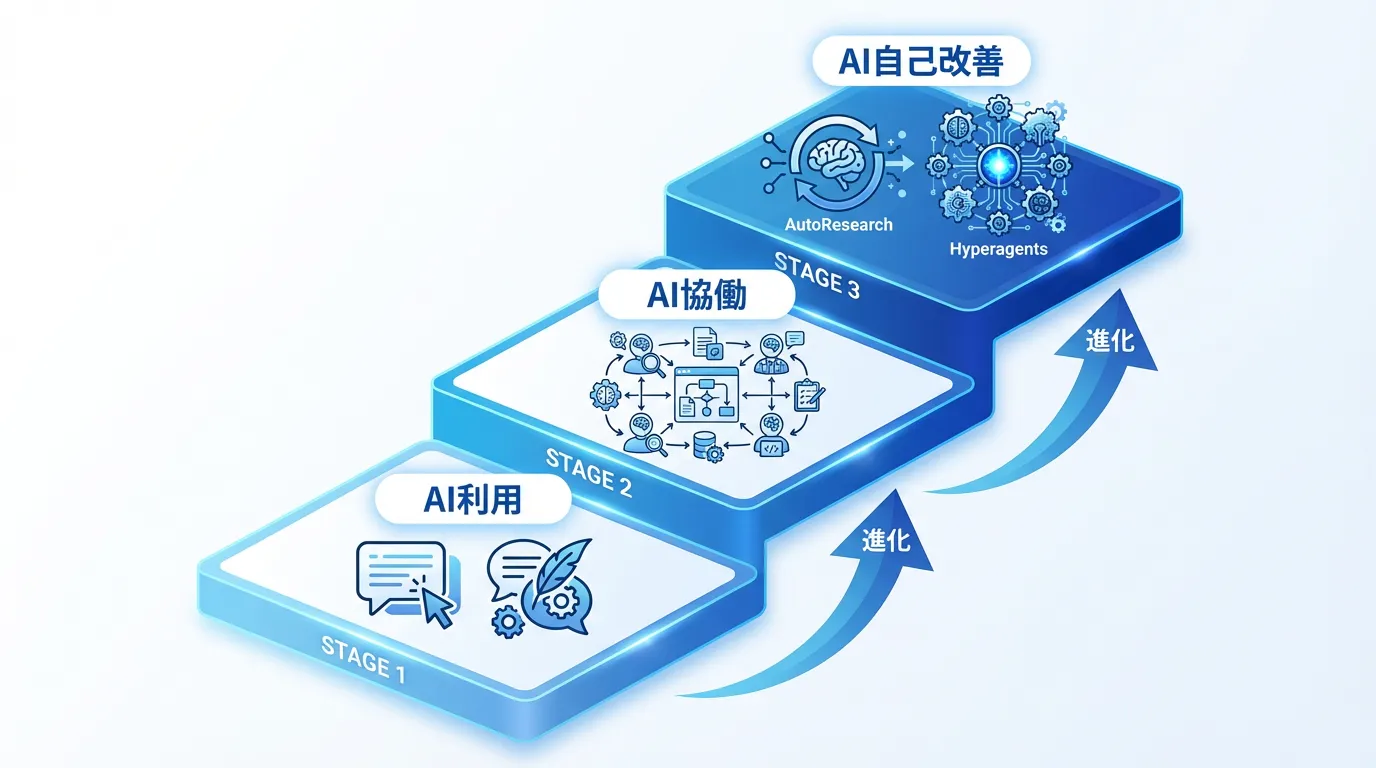
2026年3月、AIエージェント市場の転換点
2026年3月は、AIエージェントの歴史において重要な転換点となりました。月初にKarpathyのAutoResearchが公開され、8.6百万回の視聴を記録。月末にはMetaがHyperagentsを発表し、「メタ認知的自己修正」という新しい概念を提示しました。
これらの動きは、AIの進化における3つの段階を示しています:
- AI利用:人間がAIツールを使って作業を効率化する(ChatGPT、Copilot等)
- AI協働:AIエージェントが人間と協力してタスクを遂行する(マルチエージェントシステム)
- AI自己改善:AIが自律的に実験を繰り返し、自らの性能を向上させる(←今ここ)
市場調査によれば、2026年時点でAIエージェントを活用する企業は43%に達し、月平均46.9時間の業務時間削減を実現しています。しかし、多くの企業はまだ「AI利用」または「AI協働」の段階にとどまっており、「AI自己改善」の可能性を十分に活かせていません。
従来のAIツールとの決定的な違い
従来のAIツールでは、人間が学習と改善を主導していました。AIモデルの性能を向上させるには、人間がハイパーパラメータを調整し、アーキテクチャを変更し、結果を評価する必要がありました。1回の実験サイクルに数時間から数日かかることも珍しくありません。
これに対し、自己改善型AIエージェントは、設計→実行→評価→改善のループを完全に自律化します。人間は研究方向を示すだけで、後はエージェントが数百、数千の実験を自動的に実行します。結果として、人間の時間を「実験の実行」から「戦略的な設計」に集中させることができます。
誰のための技術か?
自己改善AIエージェントは、以下のような課題を持つ方々に特に有効です:
技術リード・研究チームの方々:チームの実験スピードを10倍にしたい。保守的な技術選択から脱却し、大胆な実験を高速で回したい。経営層に説得力のある実績データを示したい。
個人開発者・学習者の方々:限られた時間(週末のみ等)で最新技術をキャッチアップしたい。環境構築の壁を越えて、すぐに実験を始めたい。遠回りを避け、効率的に学習したい。
自己改善エージェントを今すぐ試したい方には、オープンアーキテクチャで無限に拡張可能な「Captain.AI」のようなプラットフォームが、実装環境として適しています。
自己改善AIエージェントの2大事例
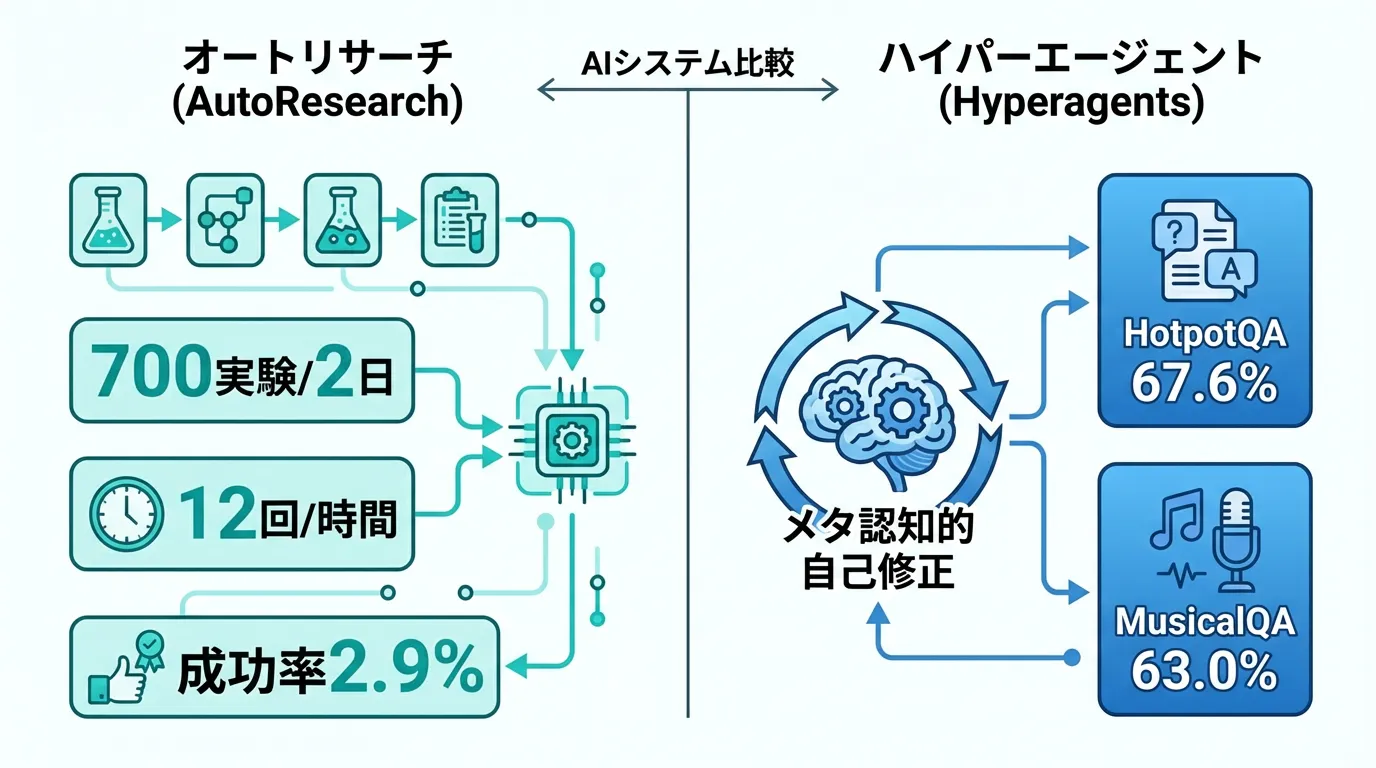
Andrej Karpathy「AutoResearch」— 一晩で100実験の衝撃
何ができるのか?
AutoResearchは、1つのGPU、1つのファイル、1つの評価指標という制約の中で動作する、驚くほどシンプルなシステムです。その動作は以下のループを繰り返します:
- 実験を設計する(コードの変更案を考える)
- コードを編集する
- 5分間学習を実行する
- 評価指標を測定する
- 改善があればgit commitで保存、なければ破棄
このシンプルなループを、約12回/時間のペースで実行します。つまり、一晩(8時間)で約100回の実験が可能です。人間が寝ている間に、エージェントは休むことなく実験を続けます。
実際の成果
Shopify CEOのTobias Lütkeは、AutoResearchを一晩動かした結果、37回の実験を実行し、19%の性能向上を達成したと報告しています。8時間の睡眠中に、人間なら数週間かかる実験量をこなしたことになります。
Karpathy自身は、2日間で700回の実験を実行し、20個の有効な最適化を発見しました。これは平均して35回に1回の成功率、わずか2.9%です。
「失敗前提」の設計思想
ここで重要な問いがあります:なぜ成功率2.9%(700回中680回失敗)でも価値があるのか?
答えは「失敗の速さ」にあります。人間が1つの実験を設計し、実装し、実行し、評価するには、少なくとも数時間、場合によっては1日以上かかります。700回の実験を人間が実行するには、約700日(約2年)が必要です。
これに対し、AutoResearchはわずか2日で700回の実験を完了します。時間効率は350倍です。
さらに重要なのは、680回の失敗も単なる「無駄」ではないという点です。各失敗は「この方向は効果がない」という貴重な知識を提供します。700回分の失敗データは、巨大な知識ベースとなります。
重要なのは「失敗を恐れない」ことではなく、「失敗を加速する」ことなのです。
オープンソースの影響
AutoResearchは完全にオープンソースで公開されており、公開数日で21,000以上のGitHub starsを獲得しました。現在では、画像認識、自然言語処理、強化学習など、多様な分野に拡張されたフォークが多数存在します。
Meta「Hyperagents」— メタ認知的自己修正の実現
AutoResearchとの違い
AutoResearchが「タスクの性能を改善する」システムであるのに対し、Hyperagentsは一歩進んで「改善方法そのものを改善する」システムです。これは「メタ認知的自己修正」と呼ばれる概念です。
人間に例えると、AutoResearchは「数学の問題を解く能力を向上させる」のに対し、Hyperagentsは「数学の勉強方法そのものを改善する能力を身につける」ようなものです。
アーキテクチャの革新性
Hyperagentsは、タスクエージェント(実際の問題を解決する)とメタエージェント(エージェントの改善方法を考える)を、単一の自己参照プログラムとして統合しています。
最も革新的なのは、メタ修正手順自体が編集可能である点です。つまり、エージェントは「自分をどう改善するか」というルールを、自分自身で書き換えることができます。
実証された性能
Meta AIとブリティッシュコロンビア大学、Vector Instituteの共同研究チームは、Hyperagentsの性能を複数のタスクで実証しました:
- 論文レビュータスク:0.0 → 0.710(初期状態からスタートして71%の精度に到達)
- オリンピック数学グレーディング:0.0 → 0.630
- 多言語コーディングベンチマーク:学習タスクで14% → 34%、未知のテストタスクで8.4% → 26.7%
特に注目すべきは、未知のテストタスクでも性能が3倍以上向上している点です。これは、単に特定のタスクに過学習したのではなく、真に「学習能力そのもの」を向上させたことを示しています。
創発的行動
Hyperagentsは、人間が明示的に指示していない機能を自律的に開発しました:
- 永続的メモリ機能:過去の実験結果を記憶し、次の実験設計に活用
- パフォーマンストラッキング機能:自分の性能の変化を追跡し、改善の方向性を判断
これらは、エージェントが「自分に必要な機能」を自分で判断し、実装したことを意味します。
2つの事例が示す2つの次元
AutoResearchとHyperagentsは、自己改善の2つの異なる次元を示しています:
- AutoResearch:速度と効率の自己改善(高速実験ループ)
- Hyperagents:学習能力そのものの自己改善(メタ認知)
理想的には、この2つのアプローチを組み合わせることで、最も強力な自己改善システムが実現できます。
自己改善AIエージェントの設計原則
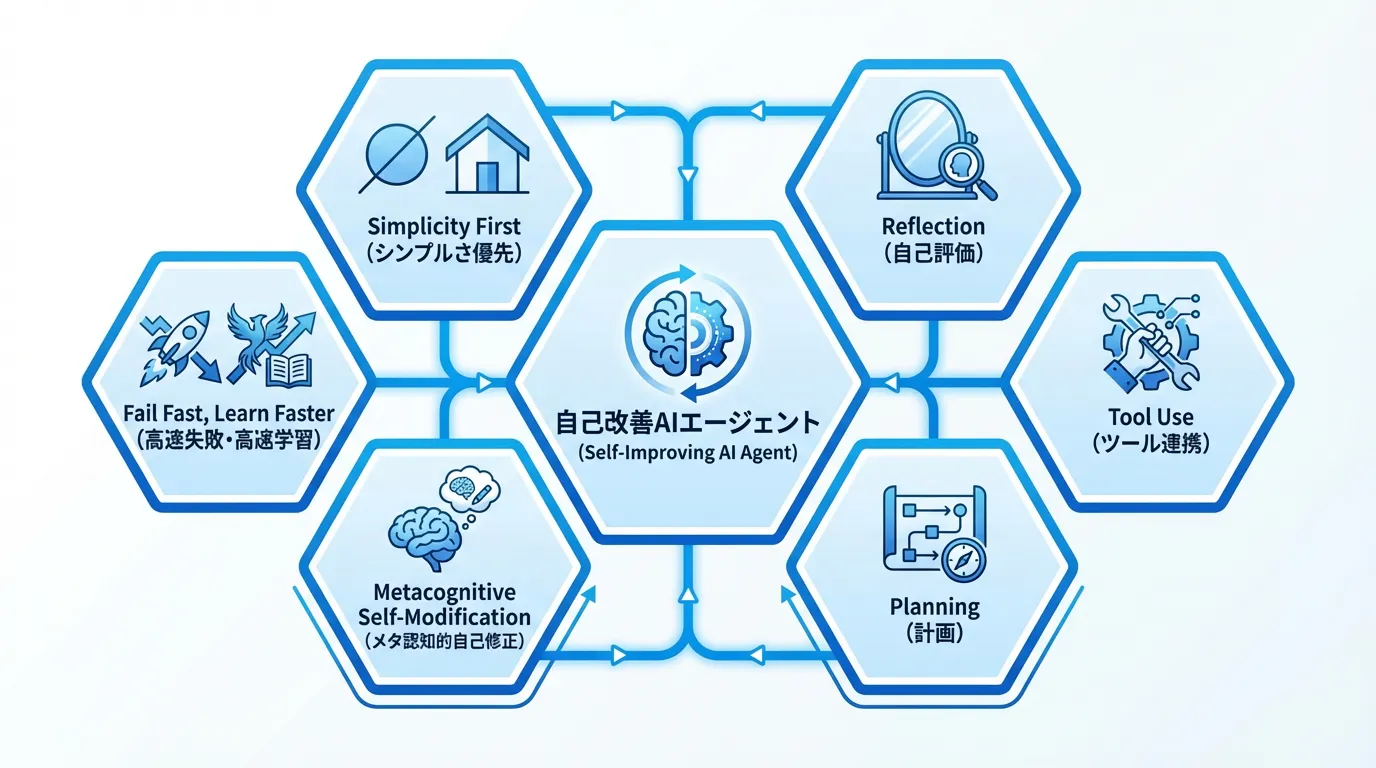
設計原則の全体像
自己改善AIエージェントの設計において、最も参考になるのはAnthropicの公式ブログ「Building Effective Agents」で提示された5つのパターンと、学術論文「Agent Design Pattern Catalogue」で提案された16のパターンです。
本記事では、これらを統合し、「自己改善ループ」に特化した6つの設計原則を提示します。
原則1:Reflection(自己評価と改善)
定義:エージェントが自身の出力を評価し、改善点を特定する能力。
AutoResearchでの実装:
- 5分間の学習を実行
- 評価指標(例:テスト精度)を計測
- 現在のベストスコアと比較
- 改善があればgit commitで保存、なければコード変更を破棄
実装パターン:
1. タスクを実行する 2. 出力を評価する(評価指標を計測) 3. 改善点を抽出する(diff分析、スコア比較) 4. keep/discardを判定する
よくある落とし穴:評価指標(メトリック)が不適切だと、エージェントは無意味な最適化を延々と繰り返します。例えば、「コード行数を減らす」という指標だけでは、機能を削除してしまうかもしれません。
解決策:複数の評価指標を組み合わせる(例:精度、速度、コードの可読性)。または、定期的に人間がチェックポイントを設ける。
原則2:Tool Use(外部ツール連携)
定義:エージェントが外部ツール(git、学習フレームワーク、評価ツール等)を自律的に使用する能力。
AutoResearchでの実装:
- git:バージョン管理、改善の履歴追跡
- PyTorch/JAX:機械学習フレームワーク
- カスタム評価スクリプト:性能測定
実装パターン:現代的なアプローチとして、MCP(Model Context Protocol)やSkillsフレームワークを使うことで、エージェントに新しいツールを簡単に追加できます。
例えば、「Captain.AI」はMCP/Skillsによる無限の拡張性を提供しており、自己改善ループに必要な任意のツールを追加できます。データベース接続、API呼び出し、ファイルシステム操作など、あらゆる外部リソースへのアクセスを、統一されたインターフェースで実現できます。
原則3:Planning(多段階計画)
定義:エージェントが長期目標を複数の実験ステップに分解する能力。
Hyperagentsでの実装:
- メタエージェントが「次にどの実験をすべきか」を計画
- タスクエージェントが計画に従って実験を実行
- 結果をもとにメタエージェントが次の計画を立てる
実装パターン:
- 人間が研究方向をmarkdownファイルで指定(例:「学習率の最適化を探る」)
- エージェントが具体的な実験リストを生成(例:学習率0.001, 0.01, 0.1を試す)
- 優先順位をつけて実行
- 結果をもとに次の方向性を決定
原則4:Metacognitive Self-Modification(メタ認知的自己修正)
定義:改善方法そのものを改善する能力。
Hyperagentsでの実装:タスクエージェントとメタエージェントを単一の自己参照プログラムとして統合。メタ修正手順自体が編集可能になっています。
実装の難しさ:この原則は最も高度であり、リスクも伴います。エージェントが自分の改善ルールを書き換えると、無限ループに陥ったり、意図しない方向に発散したりする可能性があります。
解決策:段階的に導入する。まずは原則1-3をしっかり実装し、安定してから原則4に挑戦する。また、メタ認知的修正には人間の承認プロセスを設けることを推奨します。
原則5:Fail Fast, Learn Faster(高速失敗・高速学習)
定義:失敗を前提とし、失敗から学ぶ速度を最大化する設計。
AutoResearchでの実装:
- 1実験あたり5分に制限
- 失敗してもすぐに次の実験に移行
- 失敗データも知識として蓄積
マインドセット:成功率2.9%でも価値がある理由は、失敗データが「この方向は効果がない」という知識を提供するからです。700実験分の失敗データは、成功した20実験と同等かそれ以上の価値を持つ巨大な知識ベースです。
従来のAI開発では、「失敗を避ける」ことが重視されました。慎重に設計し、確実に成功する方法を選ぶ。しかし、自己改善AIエージェントの時代では、「失敗を加速する」ことが成功への近道です。
原則6:Simplicity First(シンプルさ優先)
定義:最もシンプルなパターンから始め、必要な場合のみ複雑性を追加する。
Anthropicの鉄則:「まずシンプルに。複雑性は最後の手段」
実装例:
- Step 1:単一の評価指標、単一の実験ループ(AutoResearchの基本形)
- Step 2:複数の評価指標、実験の優先順位付け
- Step 3:メタ認知的修正(Hyperagentsレベル)
多くの開発者は、最初から複雑なマルチエージェントシステムを構築しようとして失敗します。まずは単純な自己改善ループを確実に動かすことが、成功への最短経路です。
実装の第一歩
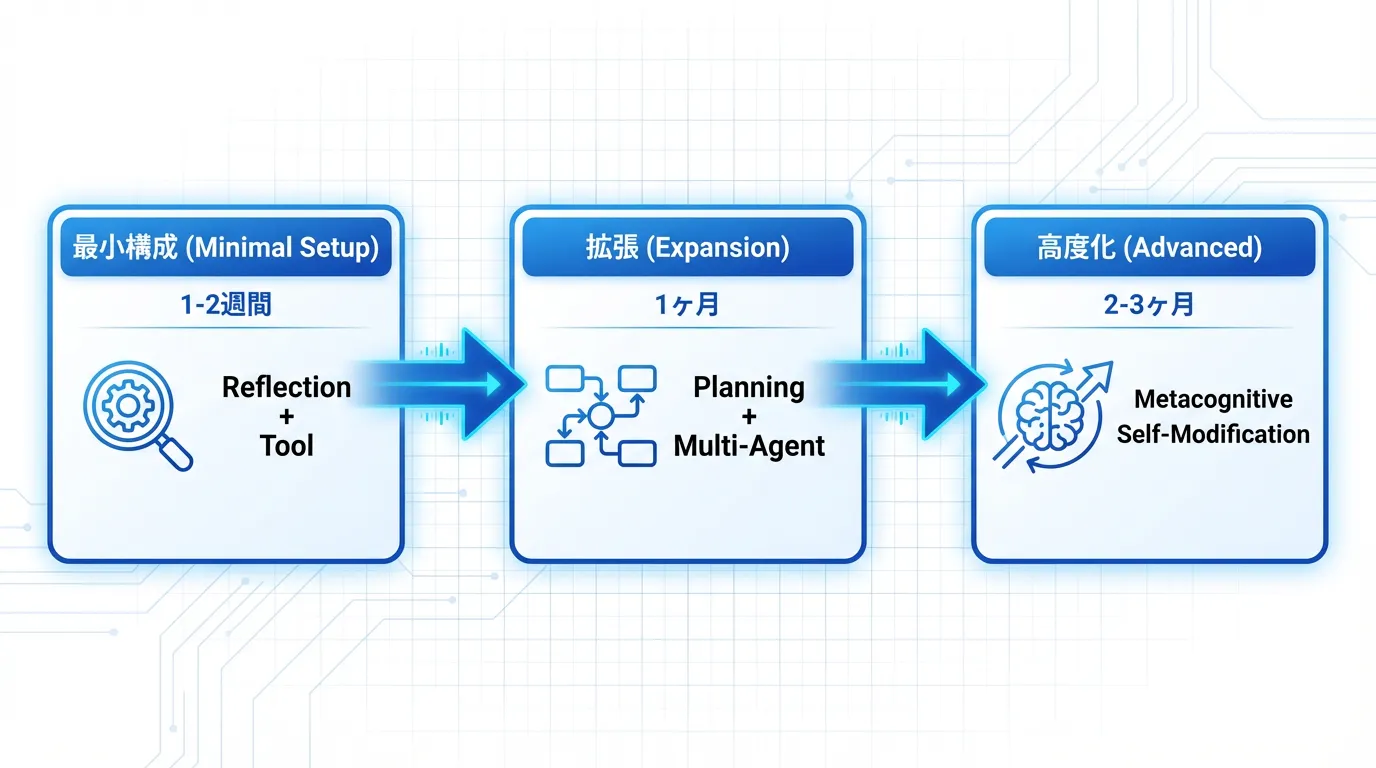
個人開発者向け:今すぐ試せる最小構成
週末の数時間で自己改善AIエージェントを体験したい方は、以下のステップで始められます:
- AutoResearchをgit clone:
git clone https://github.com/karpathy/autoresearch - 小さなタスクで実験:例えばMNIST分類(手書き数字認識)など、学習に5分程度で済むタスクを選ぶ
- 実験時間を制限:1実験5分に制限して、3-5回のループを回してみる
- git historyを確認:どのような変更が試され、どれが採用されたかを追跡する
期待される学び:
- 「失敗が速い」という新しい体験
- git historyが「学習の軌跡」になる感覚
- 人間が介入しなくても改善が進む驚き
技術リード向け:チーム導入のロードマップ
チームで自己改善AIエージェントを本格導入したい方は、以下の3フェーズで進めることを推奨します:
Phase 1:PoC(1-2週間)
- 限定的なタスク(例:特定のモデルのハイパーパラメータ調整)でAutoResearchを試す
- チーム内で「失敗前提」のマインドセットを共有する
- 計測すべき評価指標を明確にする
Phase 2:本格導入(1-2ヶ月)
- チームの主要タスクに適用する
- 評価指標(メトリック)を精緻化する(複数指標の組み合わせ、人間のチェックポイント)
- 実験結果のレビュープロセスを確立する
Phase 3:メタ認知的修正(3ヶ月〜)
- Hyperagentsパターンの検討
- 「改善の改善」に挑戦する
- 創発的行動の観察と活用
この段階的アプローチにより、チームは無理なく自己改善エージェントの導入を進められます。
よくある失敗と回避策
実装時に多くのチームが直面する3つの失敗パターンと、その回避策を紹介します。
失敗1:メトリックの罠
症状:エージェントが無意味な最適化を繰り返し、実質的な改善が得られない。
原因:不適切な評価指標。例えば「コード行数を減らす」だけを指標にすると、機能を削除してしまう。
回避策:
- 複数の評価指標を組み合わせる(例:精度、速度、メモリ使用量)
- 定期的に人間がチェックポイントを設ける(例:10実験ごとに確認)
- 「改善の定義」を明確にする
失敗2:計算コストの爆発
症状:無制限に実験を実行した結果、GPU課金が膨大になる。
原因:実験時間や回数に上限を設定していない。
回避策:
- 1実験あたりの時間上限を設定(AutoResearchは5分)
- 1日あたりの実験回数上限を設定
- ローカルLLMやオンプレミス環境を活用してコストを削減
失敗3:発散リスク
症状:メタ認知的修正が暴走し、エージェントが意図しない方向に進化する。
原因:原則4(メタ認知的自己修正)を、原則1-3が安定する前に導入した。
回避策:
- 段階的導入:まず原則1-3を確実に実装してから原則4に進む
- 人間の承認プロセス:メタ認知的修正には人間の確認を必須にする
- ロールバック機能:いつでも安全な状態に戻れるようにする
結論:「失敗を恐れない」から「失敗を加速する」時代へ
2026年、AIは「使うもの」から「協働するもの」へ、そして「自ら成長するもの」へと進化しています。
Karpathy AutoResearchが示した「700実験、680失敗」という数字は、単なる実験結果ではありません。それは、新しい時代のマインドセットを象徴しています。
従来のAI開発では、「失敗を避ける」ことが美徳とされました。慎重に設計し、確実に成功する方法を選ぶ。しかし、自己改善AIエージェントの時代では、「失敗を加速する」ことが成功への近道です。
重要なのは、失敗の数ではなく、失敗の速さです。人間なら2年かかる700回の失敗を、エージェントはわずか2日でこなします。その速度が、人間を超える学習能力を生み出します。
今日から始められるアクション:
- 今週末に試す:Karpathy AutoResearchをgit cloneして、小さなタスクで実験してみてください。
- 深く学ぶ:Hexabaseでは、AI駆動開発の実践的な知識を共有する「AI駆動開発伴走セミナー」を定期開催しています。自己改善エージェントの実装から、チーム導入の戦略まで、実務に即した内容を提供しています。
失敗を恐れず、失敗を加速する。それが、2026年のAI開発者に求められる新しいスキルです。