COLUMN
コラム
2026年03月13日
LLMはなぜ賢いのか?2600年分のテキストと1億年の計算で生まれる魔法の正体
ChatGPTに質問すれば、まるで人間のような回答が瞬時に返ってくる。毎日使っているこの「当たり前」の裏側で、一体何が起きているのか。大規模言語モデル(LLM)の仕組みを知れば、AIを「使う」から「活用する」へのシフトが見えてきます。
この記事では、LLMの動作原理を、2600年分のテキスト、1億年超の計算量、数千億のパラメータという驚異の規模感とともに、わかりやすく解説します。トランスフォーマー、アテンション、RLHFの3要素を理解することで、AI活用の戦略的優位性を手にしましょう。
1. LLMの本質は「次の単語を予測する魔法の機械」
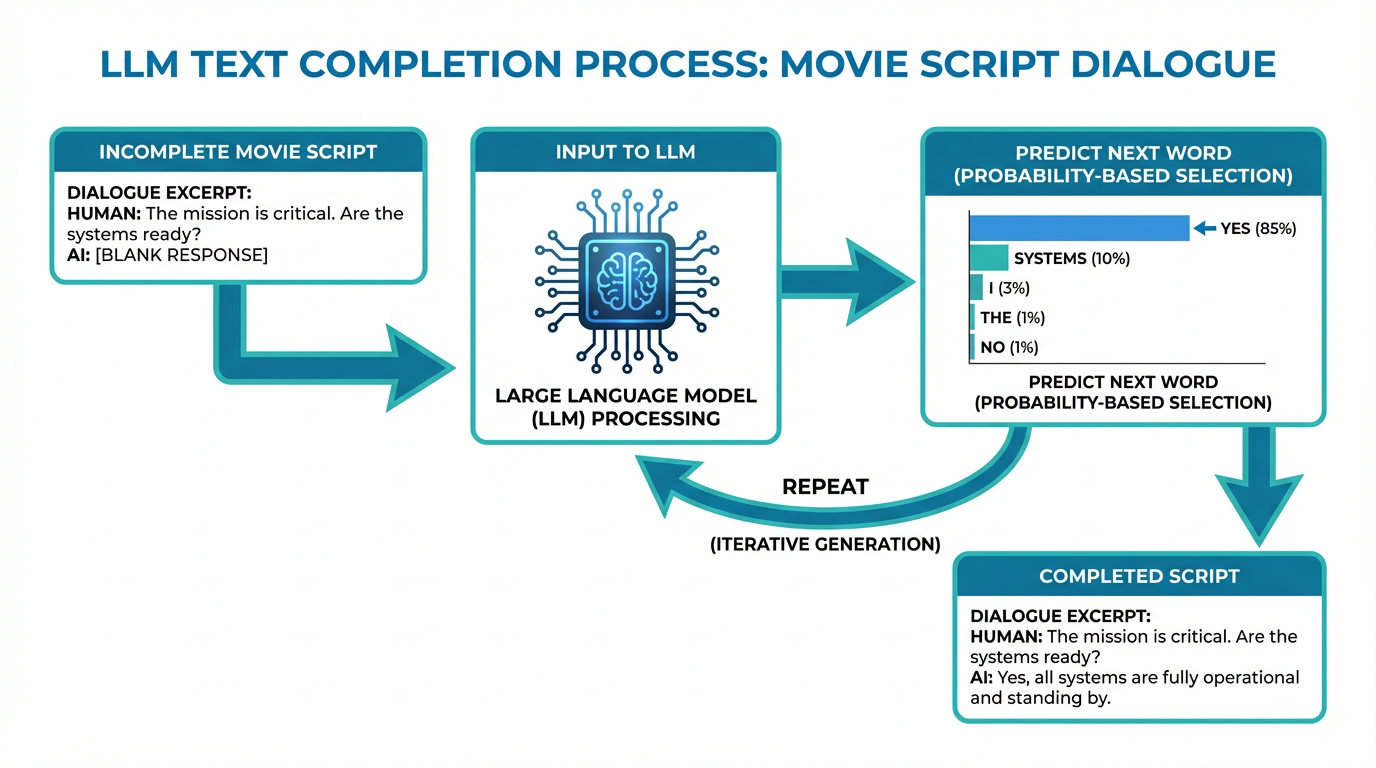
大規模言語モデル(LLM)とは何か。ひと言で表すなら、「どんなテキストに対しても、次に来る単語を予測する洗練された数学的関数」です。
想像してみてください。あなたの手元に、人とAIアシスタントが登場する映画の脚本があります。ただし、AIの回答部分だけが空欄になっている。そこに「魔法の機械」を使えば、その空欄を埋めることができる。この魔法の機械こそが、LLMの本質です。
LLMは確率で答える
重要なのは、LLMは「確実に1つの単語を予測する」のではなく、「次に来る可能性のあるすべての単語に確率を割り当てる」という点です。
たとえば、「今日の天気は」という文に対して、LLMは「晴れ」が30%、「曇り」が25%、「雨」が20%…というように、複数の選択肢に確率を与えます。そして、その確率に基づいて単語を選び、文章を完成させます。
興味深いのは、確率の低い単語もランダムに選ぶようにすると、出力がずっと自然に見える傾向があるという点です。これが、同じ質問をしても毎回異なる答えが返ってくる理由です。LLMは決定的なモデルでありながら、確率的な出力を生成することで、人間らしい柔軟性を獲得しているのです。
2. チャットボットはこうして対話を生成している
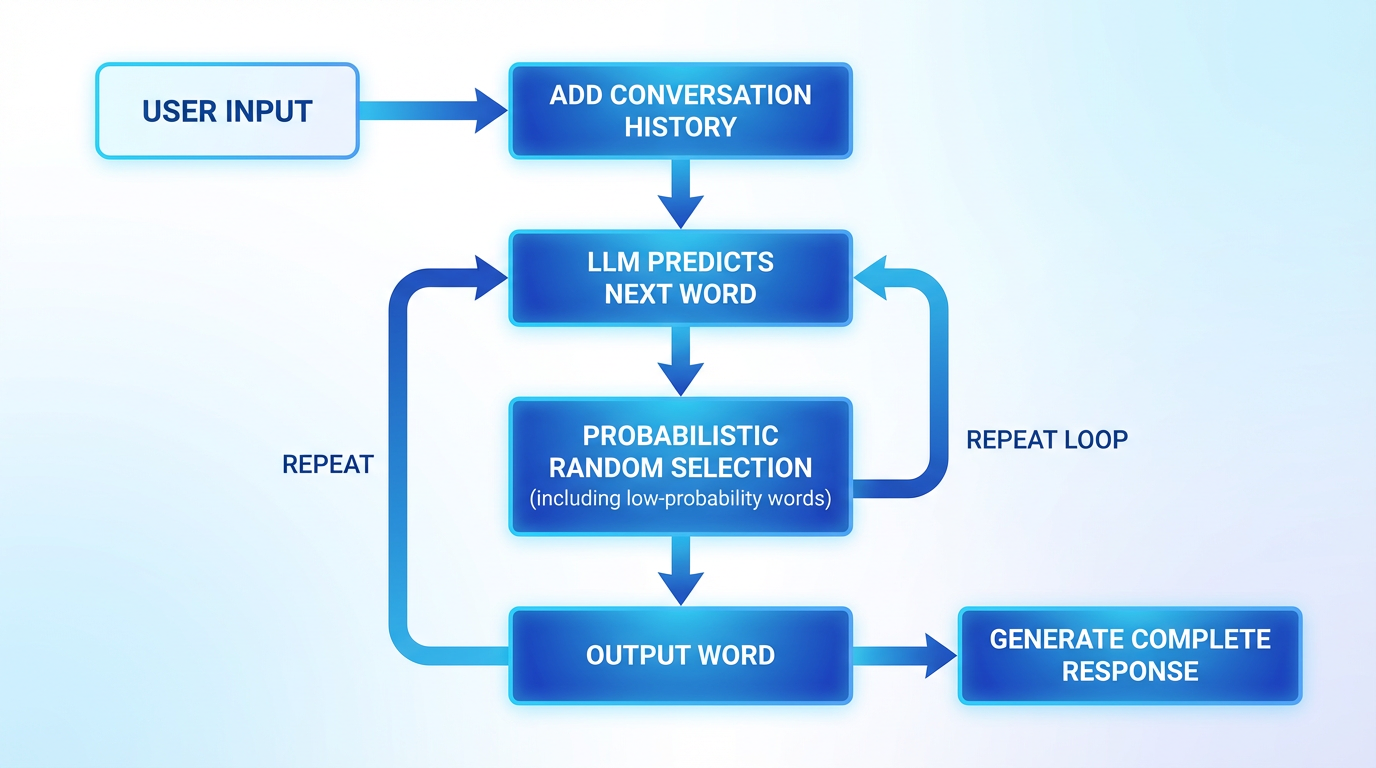
では、ChatGPTのようなチャットボットは、どのようにしてユーザーと対話を続けるのでしょうか。
その仕組みはシンプルです。まず、ユーザーと架空のAIアシスタントのやり取りを示すテキストを用意します。そこにユーザーが実際に入力した内容を付け加え、「架空のAIアシスタントが応答として言いそうな次の単語」をLLMに繰り返し予測させます。生成された単語の連鎖が、ユーザーに表示される回答となるわけです。
確率的な選択が自然さを生む
前述の通り、LLMは確率の低い単語もランダムに選びます。この「適度なランダム性」が、AIの回答に人間らしさを与えます。もし常に最も確率の高い単語だけを選ぶと、回答は正確でも機械的で退屈なものになります。
逆に、完全にランダムに選ぶと、意味不明な文章になります。LLMは、このバランスを絶妙に調整することで、流暢で魅力的な対話を実現しているのです。
3. 驚異の規模 — 2600年分のテキストと1億年の計算量
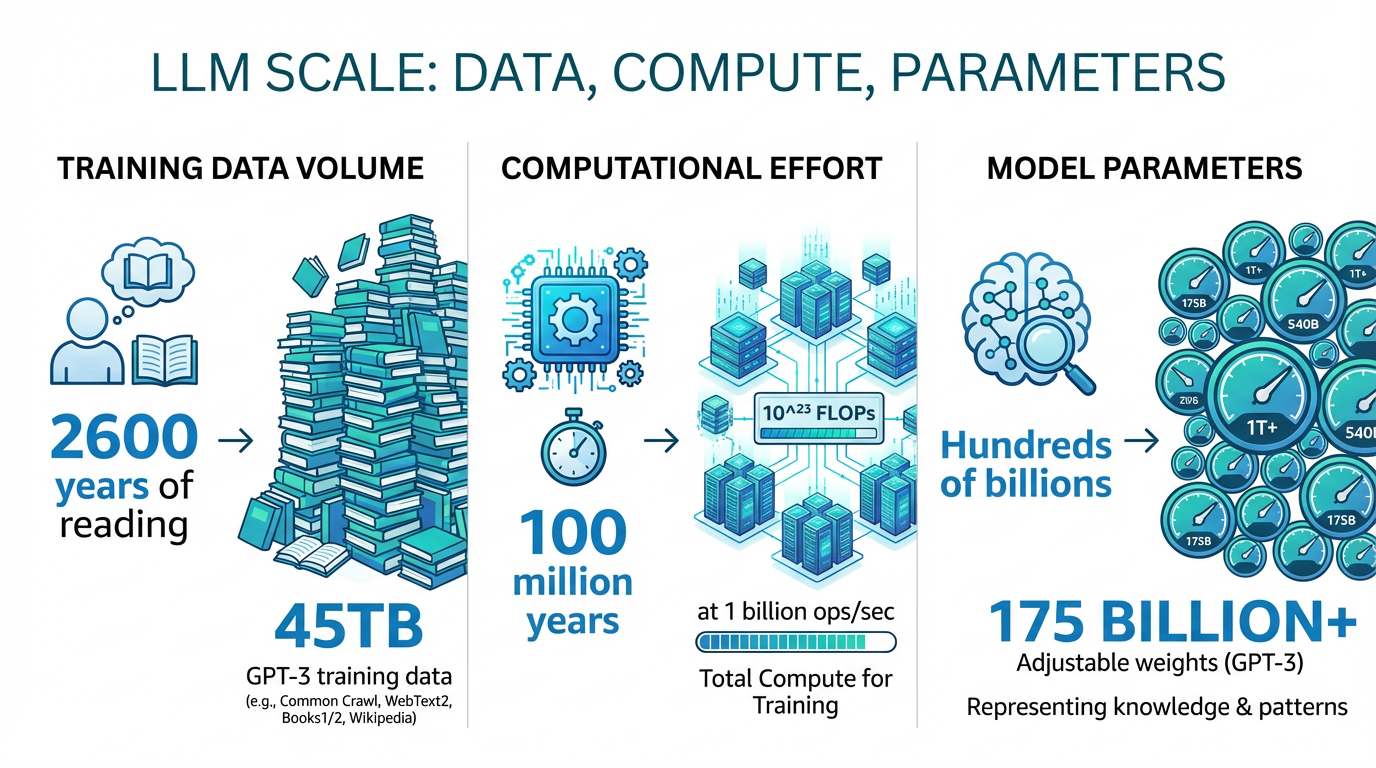
LLMの「賢さ」の秘密は、その圧倒的な規模にあります。
2600年分のテキスト
たとえば、GPT-3というモデルの訓練に使われたテキスト量を、標準的な人間が読むとしたら、24時間読み続けても2600年以上かかると言われています。それ以降の大規模モデルは、さらに膨大なデータで訓練されています。
これほどの量のテキストを処理することで、LLMは言語の文法、事実関係、文脈、さらには人間の思考パターンまでを学習します。インターネット上のあらゆる知識が、LLMの「知性」の源泉となっているのです。
数千億のパラメータ
LLMの振る舞いは、「パラメータ」または「重み」と呼ばれる連続値によって決まります。大規模言語モデルの「大規模」というのは、これらのパラメータが数千億個もあるということです。
パラメータとは、言わば機械の「ダイヤル」のようなものです。これらを調整することで、特定の入力に対してLLMが与える次の単語の確率が変わります。人間が意図的にこれらのパラメータを設定することはありません。最初はランダムに設定され、その後、膨大なテキスト例に基づいて繰り返し洗練されていきます。
1億年を超える計算量
これだけでも気が遠くなりそうですが、計算量の規模はさらに驚異的です。
仮に1秒間に10億回の足し算と掛け算を実行できるとしましょう。最も大きな言語モデルの訓練に関わるすべての演算を行うのに、どれくらいの時間がかかるでしょうか?1年?1万年?答えは、実はそれよりもずっと長いです。1億年をはるかに超えます。
この膨大な計算を可能にしているのが、GPU(グラフィックス・プロセッシング・ユニット)です。GPUは、多くの演算を並列実行するために最適化されたコンピューターチップで、LLMの訓練を現実的な時間で完了させる鍵となっています。
4. トランスフォーマーの革新 — 並列処理がLLMを加速した
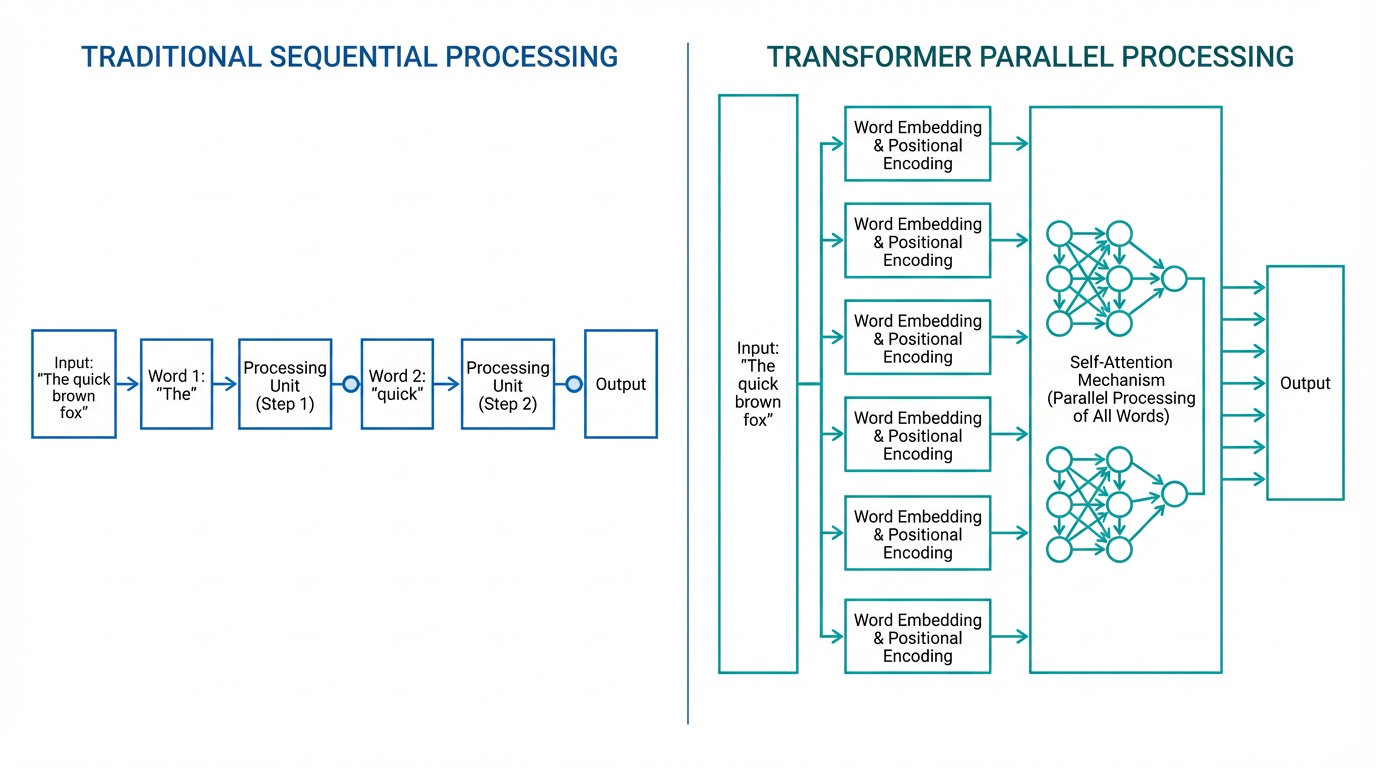
2017年、Googleの研究者チームが「トランスフォーマー」として知られる新しいモデルを発表しました。このトランスフォーマーが、現代のLLMの基盤となっています。
逐次処理から並列処理へ
それ以前の言語モデルは、テキストを1度に1単語ずつ処理していました。これでは、計算が順番に行われるため、大量のデータを処理するのに膨大な時間がかかります。
トランスフォーマーは、テキストを最初から最後まで読むのではなく、1度に並行してすべてを取り込みます。この並列処理により、訓練時間が劇的に短縮され、GPUの性能を最大限に活用できるようになりました。
単語の符号化
トランスフォーマー、そしてほとんどの言語モデルの内部での最初のステップは、各単語を長い数値のリストに対応させることです。というのも、訓練プロセスは連続値でしか機能しないので、言語をどうにか数値を使って符号化する必要があるからです。
これらの数値のリストは、それぞれ対応する単語の意味を何らかの形で符号化しているかもしれません。ただし、この段階ではまだ文脈は考慮されていません。「bank」という単語は、「銀行」と「川岸」のどちらの意味かわからないまま、同じ数値リストに変換されます。
この文脈を理解する仕組みこそが、次に説明する「アテンション」です。
5. アテンション機構 — 文脈を理解する仕組み
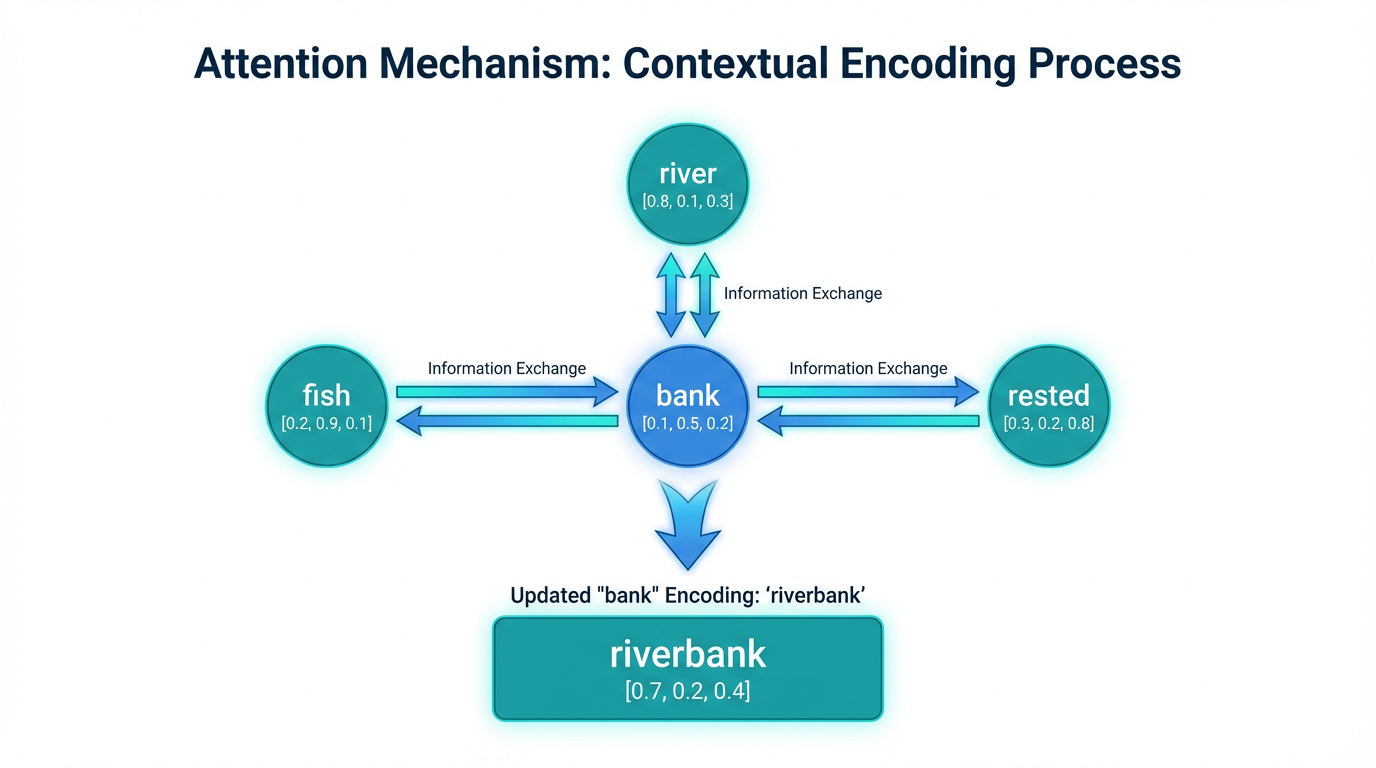
トランスフォーマーに特徴的なのが、「アテンション」として知られる特別な演算です。
単語同士が情報交換する
アテンションでは、単語を符号化した数値のリストすべてが互いに情報を交換し、周囲の文脈に基づいて符号化する意味を更新します。これは並列処理で行われます。
たとえば、「川で魚を釣った。その後、bankに座って休んだ」という文章を考えましょう。最初に「bank」を符号化した数値リストは、周囲の「川」「魚」という単語との情報交換を通じて、「川岸」というより具体的な概念を表すように更新されます。
逆に、「給料を受け取った。その後、bankに行って預金した」という文章なら、「給料」「預金」という単語との情報交換により、「銀行」という意味に更新されるわけです。
フィードフォワードニューラルネットワーク
トランスフォーマーは大抵、もう1つの演算「フィードフォワードニューラルネットワーク」という部分を持っています。これにより、モデルは訓練中に学習した言語に関するより多くのパターンを保持できるようになっています。
これら2つの基本的な演算(アテンションとフィードフォワード)を繰り返すことで、数値のリストそれぞれが豊かになります。文章中で次に続く単語を正確に予測するために必要なあらゆる情報を符号化していくのです。
最後に、この1つ目の最後のベクトル(最も右の単語の符号化)に対してある関数を適用します。このベクトルは、入力テキストのすべての文脈とモデルが訓練中に学習したことから影響を受ける機会を与えられたわけです。モデルの予測は、次に来る可能性のあるすべての単語に対する確率のように見えます。
6. 訓練の2段階 — 事前学習とRLHFで"AIアシスタント"に進化
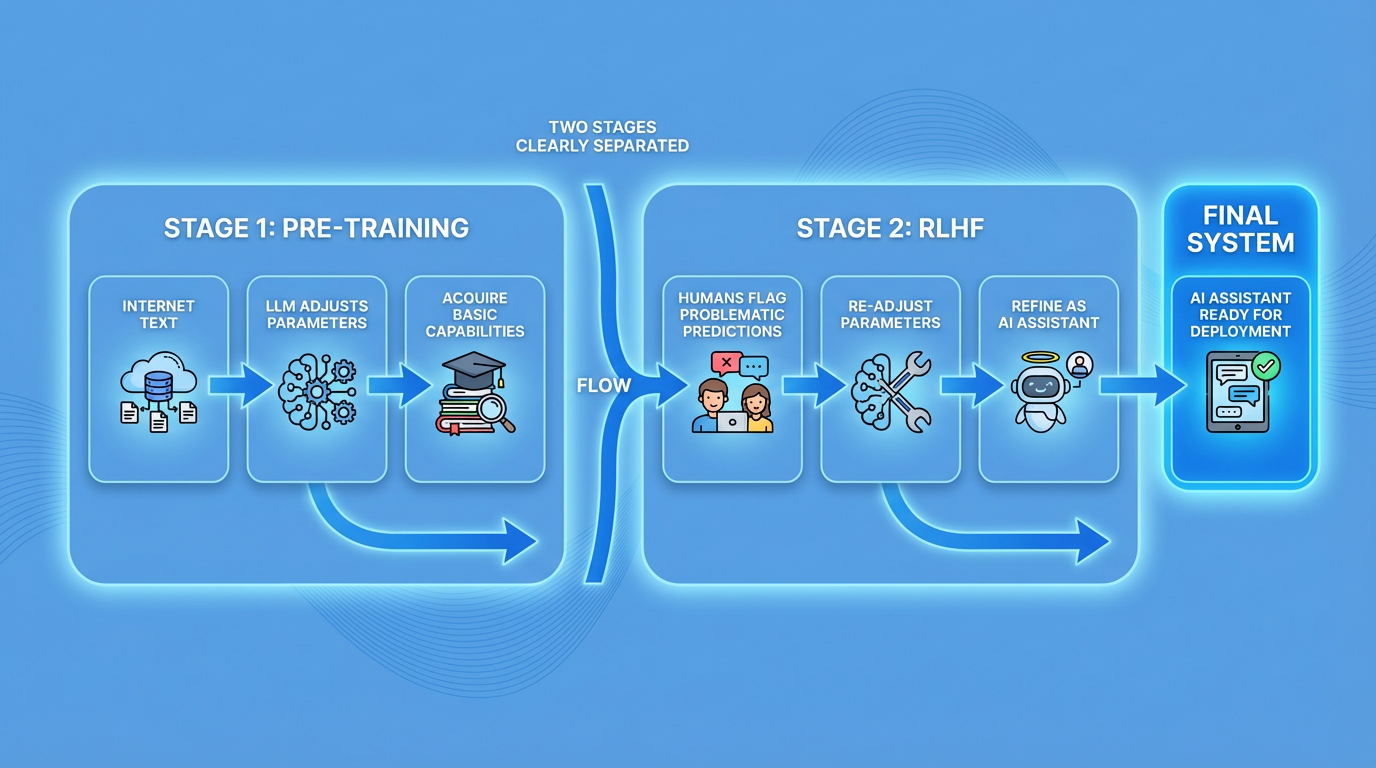
ここまでのプロセスは、「事前訓練」と呼ばれます。しかし、これだけでは完成系ではありません。
事前学習の限界
インターネット上のランダムなテキストの断片を自動補完するというのは、優秀なAIアシスタントになることとは大きく異なります。事前学習だけでは、LLMは「次の単語を予測する機械」にすぎません。
ユーザーが求めているのは、「質問に答える」「要約する」「翻訳する」といった、特定のタスクを実行できるAIアシスタントです。
人間からのフィードバックによる強化学習(RLHF)
これに対処するために、チャットボットは「人間からのフィードバックによる強化学習(RLHF)」と呼ばれる、同じくらい重要な別の種類の訓練を受けます。
役に立たない、または問題のある予測に人手でフラグを立てます。その修正によってモデルのパラメータがさらに変更され、ユーザーが好む予測を与えるようになります。
たとえば、ユーザーが「明日の天気を教えて」と質問したときに、LLMが「天気に関する詩を書きます」と応答したら、これは「問題のある予測」としてフラグが立てられます。人間が「天気予報を答えるべき」と修正することで、LLMは次第に「質問の意図を汲み取る」ことを学習します。
RLHFは、LLMを「次の単語を予測する機械」から「優秀なAIアシスタント」へと進化させる、不可欠なプロセスなのです。
7. なぜLLMは「説明困難」なのか — 創発的現象という不思議

ここまで読んで、「LLMの仕組みはわかった。でも、なぜこんなに賢いのか?」と疑問に思うかもしれません。
実は、研究者自身も、LLMがなぜ特定の予測を行うのかを完全には説明できません。
創発的現象
研究者は、トランスフォーマーやアテンションといった枠組を設計していますが、モデルの特定の振る舞いは訓練に基づく「創発的現象」です。訓練で何千億のパラメータがどのように調整されるかによって決まるため、特定の予測の理由を特定することは非常に難しくなります。
しかし、1つ確認できるのは、大規模言語モデルの予測を使ってプロンプトを自動補完すると、生成される言葉は「不気味なほど流暢で、魅力的で、さらには役に立つ」ということです。
この「説明困難だが有用」という性質こそが、LLMの不思議であり、魅力でもあります。
8. まとめ — LLMの仕組みを理解することが、AI活用の第一歩
LLMは魔法ではありません。「次の単語を予測する数学的関数」であり、トランスフォーマー、アテンション、RLHFの3要素で構成されています。
しかし、その規模は驚異的です。2600年分のテキスト、1億年を超える計算量、数千億のパラメータ。この圧倒的なスケールが、LLMに「賢さ」を与えています。
2026年、AIは「あると便利なツール」ではなく、企業の競争力を左右する必須のテクノロジになりました。AIを"使う"フェーズは終わりつつあります。これからは、AIと"協働"し、チーム全体の生産性を底上げする組織が競争優位を握ります。
LLMの仕組みを理解した上で活用することが、戦略的優位性に繋がります。
次の一歩 — 自社業務に特化したAIエージェントを構築する
LLMの仕組みを理解したあなたが次にやるべきことは、自社業務に特化したAIエージェントを構築することです。
Captain.AIなら、この記事で学んだLLMの力を、あなたの業務フローに直接組み込めます。ノーコードでスキルを定義し、チャットUIから指示するだけで、AIエージェントが業務を自動化。仕組みを知ることが、活用の第一歩です。
AIエージェントによる業務自動化に興味がある方は、まず無料相談からお気軽にお問い合わせください。