COLUMN
コラム
2026年04月28日
エージェント型コーディングで82.7%。GPT-5.5が示す、AIモデル選択の新基準
1. GPT-5.5、わずか7週間で世代交代 — 2026年4月23日発表の衝撃
2026年4月23日、OpenAIがGPT-5.5を公式発表しました。前回のGPT-5.4リリースからわずか7週間という異例のスピードでの世代交代となりましたが、このモデルは単なるマイナーアップデートではありません。
GPT-5.5は、GPT-4.5以来初のフルリトレーニングを実施したベースモデルです。事前学習コーパス、アーキテクチャ、そしてエージェント志向の学習目的が全て刷新され、モデルが自分でツールを使い、計画を立てて、長時間の作業をやり抜くことを最初から想定して設計されています。
ビジネス+ITの報道によると、GPT-5.5は複雑な自律型タスクの遂行に特化し、マルチステップの作業をユーザーの継続的な指示なしで完遂する能力を備えており、単に賢さが向上しただけではなく、AIエージェントとして実際の仕事を最後まで進める力が大幅に強化されています。
この進化は、コーディング支援ツールを日常的に使うエンジニアにとって見過ごせない変化です。従来の「質問に答えるAI」から「タスクを完遂するAI同僚」へのシフトが、ここ数週間で加速しているのです。
最新のAIモデルを活用した開発手法について学びたい方は、HexabaseのAI駆動開発伴走セミナーで実践的な使い分け戦略を学ぶことができます。
2. SWE-Bench Pro 結果 — Claude Opus 4.7が5.7ポイント先行
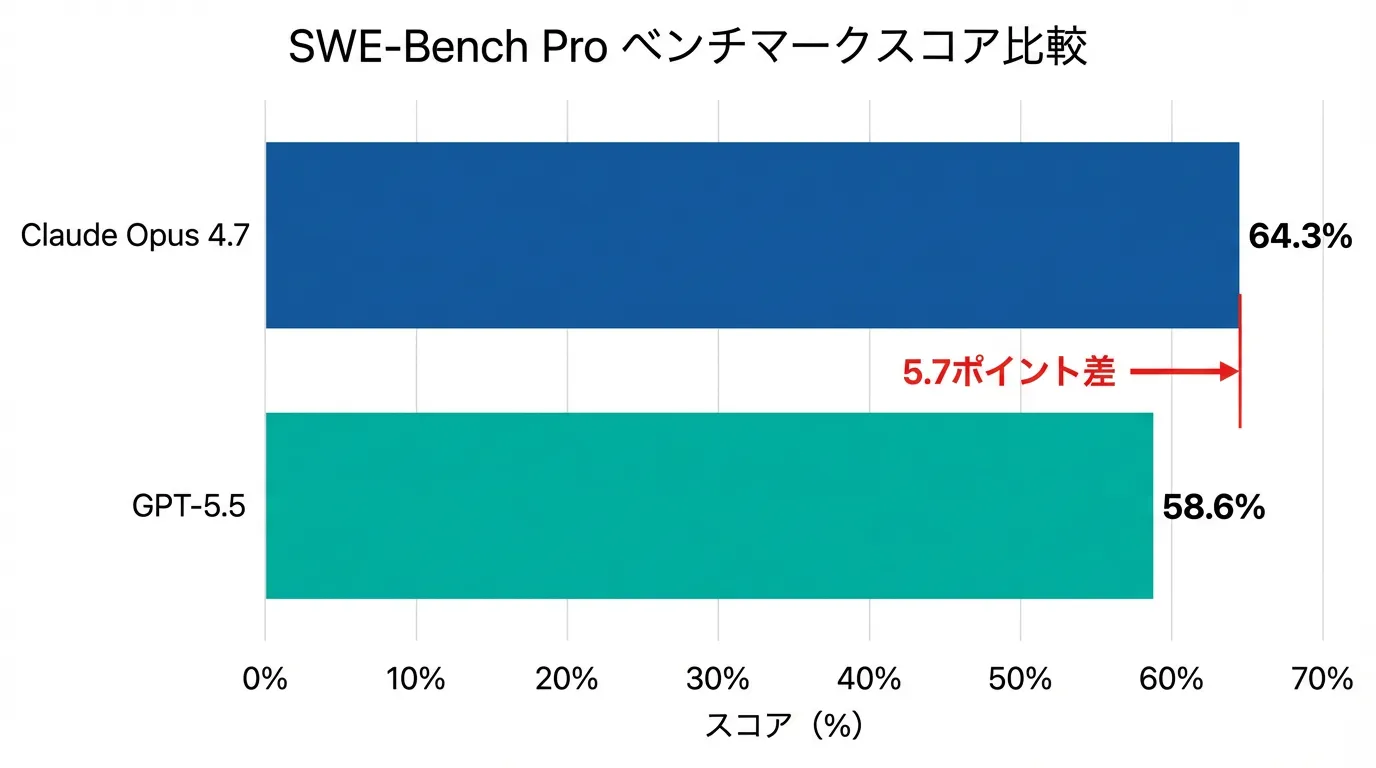
実世界のGitHubイシュー解決能力を測るSWE-Bench Proでは、公式リーダーボードによるとClaude Opus 4.7が64.3%のスコアを記録し、GPT-5.5の58.6%を5.7ポイント上回りました。
このベンチマークは、実際のオープンソースプロジェクトから抽出された問題をAIモデルに解かせるもので、大規模コードベース全体の広範な構造推論が必要なタスクが含まれています。MindStudioの詳細分析によれば、難易度が高いコード修正タスク、特に既存のコードベースへの深い理解と慎重な変更が求められる場面では、Claude Opus 4.7がやや優位に立っています。
複数のファイルにまたがる依存関係の把握や、既存のアーキテクチャパターンを崩さない修正の提案において、Claudeの強みが顕著に表れました。ただし、この数値だけで「Claude Opus 4.7の方が優れている」と結論付けるのは早計です。次のセクションで見るように、タスクの性質によって最適なモデルは変わります。
3. Terminal-Bench 2.0 — GPT-5.5がエージェント型コーディングで82.7%を達成

一方、Terminal-Bench 2.0では状況が逆転します。Epoch AIのベンチマークページによると、このベンチマークは計画・実行・検証のループを繰り返すエージェント型タスクを評価するもので、Interesting Engineeringの報道の通り、GPT-5.5が82.7%を記録し、Claude Opus 4.7の69.4%を大きく上回りました。
エージェント型コーディングとは、AIが一度のプロンプトで完結する作業ではなく、複数のステップを自律的に実行し、途中で得られた情報を次のアクションに活かす能力を指します。例えば以下のようなタスクです:
- 自律的なツール選定:ファイル検索、コード実行、テスト実行など、目的達成に必要なツールを自分で判断して使う
- 動的な計画修正:エラーが発生したら原因を分析し、アプローチを変更する
- 長時間の作業継続:数十ステップにわたる作業を、人間の介入なしで完遂する
GPT-5.5は、この「自律的にタスクを完遂する力」において業界最高水準に到達しました。正確なツール使用とファイルナビゲーションが必要な問題で、特に優位性を発揮しています。
複数のAIモデルを統合管理し、タスク別に最適なモデルを自動選択できる仕組みが求められている方は、Captain.AIで実現できます。Captain.AIはMCP/Skillsフレームワークによる無限の拡張性を持ち、記事で解説した3モデル戦略を1つのプラットフォームで運用可能です。
4. コスト・速度・トークン効率 — API料金2.5倍の価値はあるか
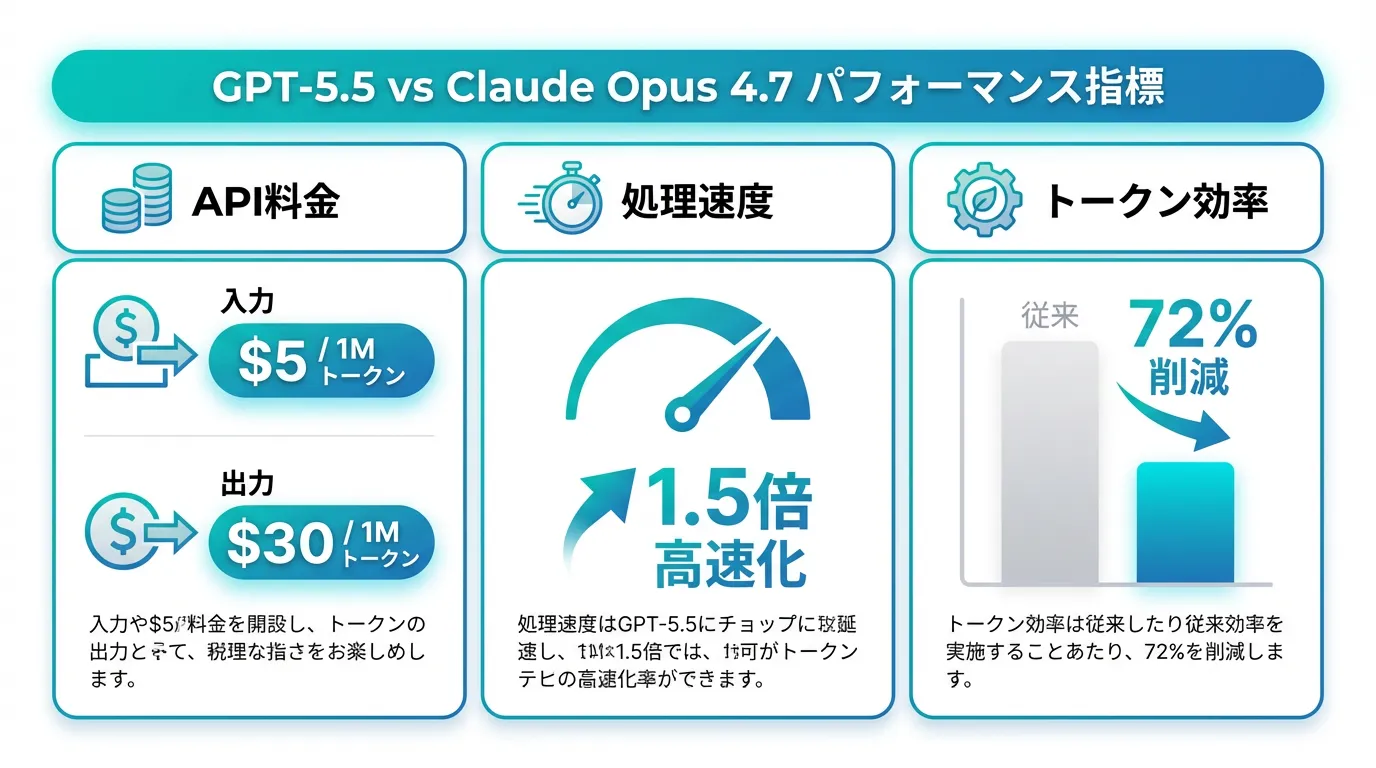
Knightliの詳細レポートによると、GPT-5.5のAPI料金は、入力$5/100万トークン、出力$30/100万トークンと設定されています。GPT-5.4と比較すると約2.5倍のコストになりますが、その代わりに以下の改善が得られます:
- 処理速度1.5倍向上:同じタスクをより短時間で完了
- トークン効率72%改善:同じコーディングタスクで、Claude Opus 4.7比で約72%少ない出力トークンを生成
- コンテキストウィンドウ1M:大規模コードベースを一度に扱える
トークン効率の改善は、実際のコスト計算において重要な要素です。出力トークンが72%削減されるということは、長い応答を生成するタスクでは実質的なコストがAPI料金の値上げ分を相殺する可能性があります。
どんな場面でGPT-5.5を選ぶべきか
コストと性能のバランスを考えると、以下のような場面でGPT-5.5の価値が最大化されます:
- 複数ステップの自律タスク:エージェント型の作業で、82.7%の成功率は他モデルを大きく上回る
- 高速な反復開発:処理速度1.5倍により、試行錯誤のサイクルが短縮される
- 長文生成タスク:トークン効率72%改善により、実質コストが抑えられる
逆に、既存コードベースへの慎重な修正や、大規模な構造推論が必要なタスクでは、Claude Opus 4.7の方が適している場面もあります。重要なのは、モデルの性能差を理解した上で、タスクに応じた使い分けを行うことです。
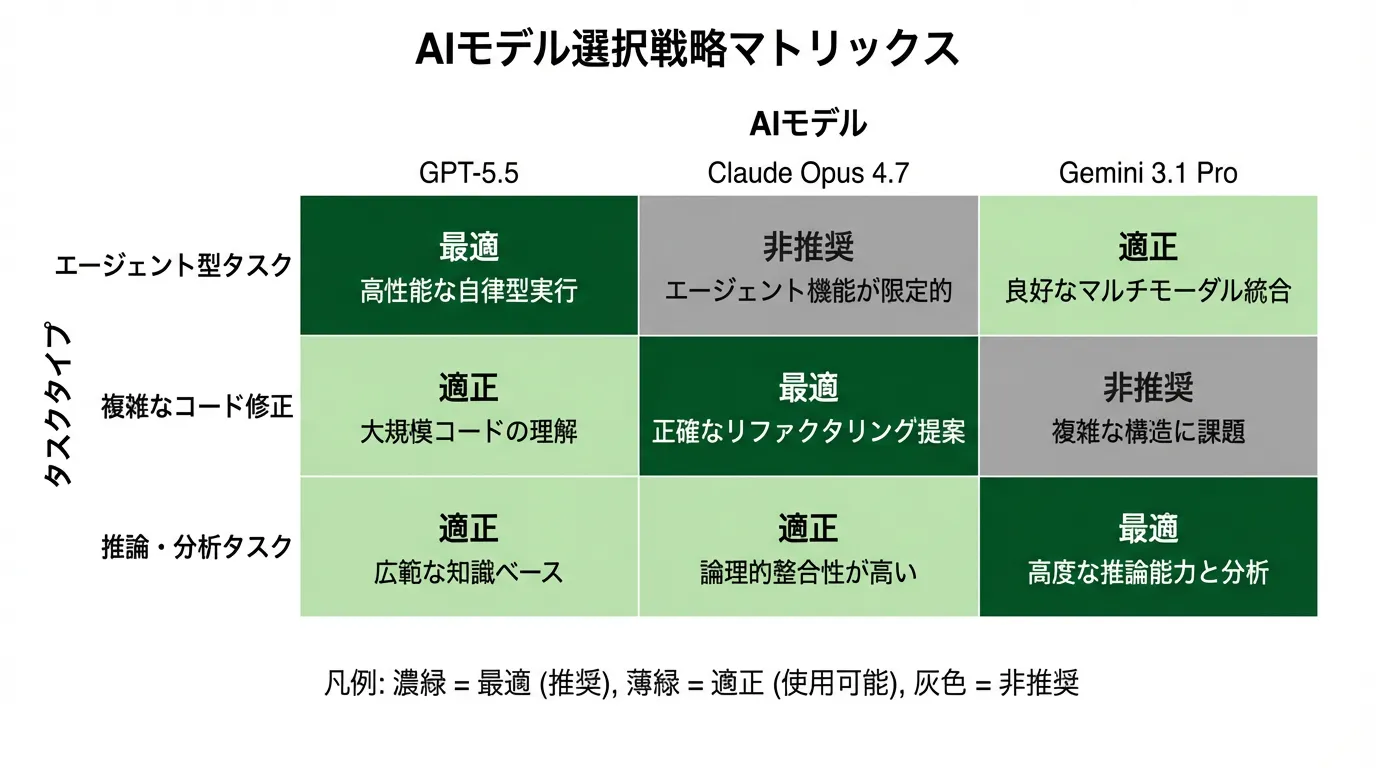
5. 2026年の業界スタンダード —「GPT-5.5=エージェント、Claude=コーディング、Gemini=推論」の3モデル使い分け
2026年4月時点で、MarkTechPostの分析が指摘するように、開発現場では「単一モデルで全てをカバーする時代は終わった」という認識が広がっています。GPT-5.5とClaude Opus 4.7のベンチマーク結果が示すように、どちらのモデルも優秀ですが、異なる種類のコーディング作業で優れています。
業界では、以下のようなタスク別の使い分けが新しいスタンダードとして定着しつつあります:
- GPT-5.5 — エージェント型タスク:自律的にツールを使い、計画を立てて長時間の作業を完遂する場面。Terminal-Bench 2.0で82.7%を記録した強みを活かす
- Claude Opus 4.7 — 複雑なコード修正:既存コードベースへの深い理解と慎重な変更が必要な場面。SWE-Bench Proで64.3%を記録した構造推論力を活かす
- Gemini 3.1 Pro — 推論・分析タスク:大規模データの分析や、論理的な推論が必要な場面。2Mトークンの長大なコンテキストウィンドウを活かせる
この3モデル戦略は、ベンチマークスコアだけでは見えない実務適合度を重視しています。GPT-5.5がSWE-Bench Proで5.7ポイント差をつけられても、エージェント型タスクにおける圧倒的な優位性(Terminal-Bench 2.0で13.3ポイント差)があるため、タスクの性質によって価値が逆転します。
チームでの導入戦略
開発チームでこの3モデル戦略を実践する場合、以下のような段階的アプローチが推奨されます:
- Phase 1: タスク分類の明確化:チーム内のコーディングタスクを「エージェント型」「コード修正」「推論・分析」の3つに分類
- Phase 2: モデル選択ガイドラインの作成:各タスク分類に対して推奨モデルを明記したガイドラインを用意
- Phase 3: 統合管理の検討:複数モデルを1つのプラットフォームで管理し、タスク別の自動選択を実現
GPT-5.5とClaudeの使い分けをチームで実践したい方は、Hexabaseの無料相談で導入支援を受けることができます。
6. まとめ — モデルの性能差より、使い分けの時代
GPT-5.5の登場により、AIモデル選択の基準が「どちらが優れているか」から「どのタスクにどのモデルが最適か」へとシフトしました。SWE-Bench Proで5.7ポイント差をつけられても、Terminal-Bench 2.0で13.3ポイント差をつけ返すGPT-5.5の姿は、単一のベンチマークスコアだけでモデルを評価することの限界を示しています。
重要なのは、各モデルの強みを理解し、タスクの性質に応じて最適なモデルを選択することです。エージェント型タスクにはGPT-5.5、複雑なコード修正にはClaude Opus 4.7、大規模データ分析にはGemini 3.1 Proという3モデル戦略は、2026年の開発現場における新しいスタンダードとなりつつあります。
API料金2.5倍という数字だけを見れば躊躇するかもしれませんが、処理速度1.5倍、トークン効率72%改善、そして何より82.7%のエージェント型タスク成功率を考えれば、適切な場面でGPT-5.5を選択する価値は十分にあります。
モデルの性能差を気にする時代から、使い分けの時代へ。あなたのチームは、この新しい選択基準を活かせていますか?